
Abstrak
Percobaan difraksi sinar-X serbuk (pXRD) merupakan landasan untuk karakterisasi struktur material. Meskipun aplikasinya tersebar luas, analisis difraktogram pXRD masih menghadirkan tantangan signifikan terhadap otomatisasi dan hambatan dalam penemuan throughput tinggi di laboratorium self-driving. Pembelajaran mesin menjanjikan untuk mengatasi hambatan ini dengan mengaktifkan analisis difraksi serbuk otomatis. Kesulitan penting dalam menerapkan pembelajaran mesin ke domain ini adalah kurangnya kumpulan data eksperimen berukuran cukup, yang telah membatasi peneliti untuk berlatih terutama pada data simulasi. Namun, model yang dilatih pada pola pXRD simulasi menunjukkan generalisasi terbatas pada pola eksperimen, terutama untuk pola eksperimen berkualitas rendah dengan tingkat kebisingan tinggi dan latar belakang tinggi. Dengan Open Experimental Powder X-ray Diffraction Database (opXRD), kami menyediakan kumpulan data difraktogram serbuk eksperimental berlabel dan tidak berlabel yang tersedia secara terbuka dan mudah diakses. Data opXRD berlabel dapat digunakan untuk mengevaluasi kinerja model pada data eksperimen dan data opXRD tak berlabel dapat membantu meningkatkan kinerja model pada data eksperimen, misalnya, melalui metode pembelajaran transfer. Kami mengumpulkan 92.552 difraktogram, 2.179 di antaranya berlabel, dari spektrum kelas material yang luas. Kami berharap upaya berkelanjutan ini dapat memandu penelitian pembelajaran mesin menuju analisis data pXRD yang sepenuhnya otomatis dan dengan demikian memungkinkan laboratorium material self-driving di masa mendatang.
1 Pendahuluan
Munculnya eksperimen dengan throughput tinggi memiliki prospek untuk mempercepat kecepatan penemuan material secara signifikan [ 1 ]. Sintesis dan karakterisasi material baru menjadi semakin efisien dan otomatis, meningkatkan throughput sampel dalam jalur eksperimen [ 2 , 3 – 4 ].
Bahasa Indonesia: Setelah membuat material baru, sejumlah teknik analisis dapat digunakan untuk mengkarakterisasi sampel. Satu metode yang dapat digunakan untuk identifikasi fase, kuantifikasi fase, karakterisasi ukuran butiran, dan untuk menentukan struktur kristal dari material baru adalah difraksi sinar-X serbuk (pXRD). Saat menggunakan pengukuran pXRD, struktur kristal biasanya ditentukan melalui penyempurnaan Rietveld. Dalam penyempurnaan Rietveld, model struktur kristal awal dipasangkan ke difraktogram yang diamati dengan memperbarui model struktural secara berulang. Setiap pembaruan model struktural berupaya meminimalkan perbedaan antara difraktogram yang diamati dan difraktogram yang disimulasikan dari model struktural saat ini [ 5 , 6 ]. Karena penyempurnaan Rietveld adalah metode optimasi lokal, hasil dari prosedur penyempurnaan umumnya hanya sebaik model struktural awal tempat proses dimulai.
Melakukan penyempurnaan Rietveld secara manual memakan waktu dan sering kali memerlukan pengetahuan ahli. Penyempurnaan ini tidak dapat diskalakan hingga tingkat yang diperlukan untuk mengimbangi kemajuan dalam throughput dan efisiensi pada langkah-langkah lain dari alur eksperimen. Proses penyempurnaan mengharuskan operator untuk menentukan model struktural awal tempat penyempurnaan dapat dimulai dan juga nilai awal untuk parameter yang mencirikan latar belakang [ 7 ]. Model struktural biasanya diperoleh dengan menggunakan perangkat lunak pencarian-pencocokan, yang mengidentifikasi struktur kristal dengan pola difraksi serbuk yang serupa dari basis data struktur kristal dengan pola difraksi serbuk yang menyertainya. Namun, model struktural awal yang diperoleh dari basis data tersebut tidak dijamin akan menghasilkan solusi struktur yang akurat melalui penyempurnaan Rietveld, terutama untuk struktur baru. Selain itu, upaya untuk menyempurnakan semua parameter struktur kristal sekaligus diketahui menghasilkan hasil yang tidak fisik [ 4 ]. Oleh karena itu, parameter disempurnakan secara berulang, dengan setiap iterasi hanya menyempurnakan serangkaian parameter yang terbatas. Menemukan urutan yang benar untuk menyempurnakan parameter struktur dan menemukan nilai yang benar untuk parameter latar belakang awal keduanya menghadirkan masalah yang menambah kesulitan proses penyempurnaan.
Pembelajaran mesin memiliki potensi untuk mempercepat analisis manual difraktogram bubuk dan mengimbangi lingkungan eksperimen otomatis berthroughput tinggi [ 8 , 9 ]. Model dapat dilatih untuk memprediksi informasi struktur kristal secara langsung dengan difraktogram, atau dapat digunakan untuk mengotomatiskan alur kerja penyempurnaan konvensional. Dalam kasus terakhir, model pertama-tama akan memprediksi struktur kristal awal [ 9 ], yang kemudian disempurnakan oleh model kedua yang dilatih untuk melakukan proses penyempurnaan [ 10 ]. Sejauh ini, karena tidak adanya kumpulan data berlabel dengan difraktogram eksperimental [ 11 ], pembelajaran mesin dalam domain ini sebagian besar bergantung pada difraktogram yang disimulasikan dari struktur yang diketahui [ 12 , 13 ] atau, yang terbaru, dari kristal sintetis yang dihasilkan [ 14 ]. Model yang dilatih pada dataset dengan difraktogram simulasi telah menunjukkan kinerja yang kuat dalam memprediksi fase [ 12 , 15 , 16 ] , parameter kisi [ 17-19-20 ] , grup ruang [ 12-25 , 14 , 20-26 ], dan ukuran kristalit [ 17 , 26 ] dari difraktogram simulasi. Namun, kinerjanya menurun secara substansial ketika model ini diterapkan pada data yang berasal dari eksperimen [ 11 , 14 , 20 , 21 , 23 ] . Perbedaan dalam kinerja ini muncul karena ketidaksempurnaan dalam data eksperimen, yang tidak ada dalam pola difraksi yang dimodelkan dalam kondisi ideal. Hal ini dibahas lebih rinci di bawah ini.
Baik kumpulan data berlabel maupun tak berlabel dari difraktogram bubuk eksperimental memiliki nilai signifikan untuk analisis pXRD berbasis pembelajaran mesin, khususnya yang berkaitan dengan menjembatani kesenjangan kinerja antara domain simulasi dan eksperimental. Data eksperimental berlabel dapat digunakan untuk menguji dan membandingkan pendekatan analisis otomatis yang ada dan yang baru. Hal ini memungkinkan para peneliti untuk mengukur seberapa baik model tertentu akan berkinerja dalam kondisi dunia nyata jika diintegrasikan ke dalam jalur eksperimen otomatis. Data eksperimental yang tidak berlabel memungkinkan para peneliti pembelajaran mesin untuk mengevaluasi seberapa dekat simulasi mereka mewakili data eksperimental dan memodifikasi algoritme simulasi mereka sebagaimana mestinya. Data yang tidak berlabel juga dapat menemukan aplikasi dalam pendekatan pembelajaran transfer untuk mentransfer kemampuan model dari domain difraktogram simulasi ke domain difraktogram eksperimental. Sementara beberapa basis data bubuk eksperimental ada, utilitasnya dibatasi oleh fakta bahwa basis data tersebut kecil atau tidak dapat diakses secara terbuka.
Dalam karya ini, kami memperkenalkan basis data difraksi sinar-X serbuk terbuka (opXRD) yang menampilkan berbagai pola yang dikumpulkan dari eksperimen. Tujuan dari karya ini adalah untuk memperkenalkan dan menyebarluaskan kumpulan data pXRD eksperimental terbuka yang besar, yang membuka jalan bagi studi masa depan yang akan mengevaluasi dan membandingkan dampaknya pada kinerja model. Dengan total 92.552 pola yang dikumpulkan dari 6 lembaga kontributor, basis data opXRD melebihi ukuran basis data terbesar sebelumnya dari data difraksi serbuk eksperimental yang dapat diakses secara terbuka dengan dua kali lipat. Sejauh pengetahuan kami, basis data terbesar dari jenis ini adalah basis data RRUFF, yang berisi 1290 pola difraksi serbuk eksperimental [ 27 , 28 ]. Kumpulan data komersial yang lebih besar seperti PDF5+ [ 29 ] dan Linus Pauling File [ 30 ] ada, tetapi utilitasnya dibatasi oleh biaya dan lisensi yang ketat. Ketentuan lisensi kumpulan data komersial, seperti PDF5+ dan Linus Pauling File, melarang atau membatasi publikasi model yang dilatih pada datanya. Sebaliknya, basis data opXRD bersifat gratis dan tidak memberlakukan batasan apa pun tentang cara penggunaan datanya. Gambar 1 memberikan gambaran umum tentang alur kerja pembelajaran mesin yang diaktifkan dan didukung oleh basis data opXRD.
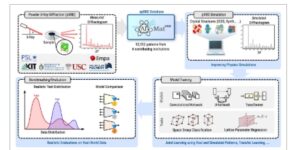
GAMBAR 1
Buka di penampil gambar
Kekuatan Gambar
Pola difraksi sinar-X serbuk eksperimental (pXRD) dari beberapa kontributor dikumpulkan dalam basis data opXRD. Basis data akses terbuka yang diusulkan berisi data eksperimental bertujuan untuk mendukung setiap langkah dalam alur kerja pembelajaran mesin terkait pXRD dengan menginformasikan simulasi fisika yang lebih baik, menyediakan data pelatihan model, dan menyediakan dasar untuk evaluasi kinerja yang realistis.
Dari 92.552 pola dalam basis data opXRD, 2179 pola hadir dengan setidaknya informasi struktural parsial dari sampel yang mendasarinya. Dari 2179 pola berlabel ini, 912 memiliki label struktur kristal penuh. Sementara fraksi sampel dengan label struktural (2,35%) mungkin tampak kecil, fraksi ini mewakili koleksi pola pXRD yang diturunkan secara eksperimental dan dianotasi struktur yang tersedia secara terbuka terbesar. Sebagai perbandingan, basis data RRUFF, yang sering digunakan untuk model ML pembanding, berisi label parsial untuk 1290 pola, tetapi tidak ada koordinat atomik. Basis data opXRD lebih besar ukurannya, lebih kaya label, dan lebih luas dalam pengaturan eksperimental yang direpresentasikan dibandingkan dengan kumpulan data yang tersedia secara terbuka sebelumnya. Mengingat sifat pelabelan manual yang secara inheren padat karya dalam analisis pXRD, tidak praktis untuk mengharapkan kumpulan data berlabel lengkap pada skala kumpulan data pelatihan yang disimulasikan, yang umumnya melebihi 106 pola [ 14 , 28 , 31 ]. Oleh karena itu, di samping opsi pembandingan model dan metode pada subset berlabel, opXRD dirancang untuk melengkapi set data simulasi yang luas. Hal ini dapat dicapai melalui penyesuaian parameter simulasi dengan membandingkan dengan subset tak berlabel dari basis data, dan melalui strategi pembelajaran transfer. Sekarang kami ingin membahas kedua opsi ini untuk memanfaatkan bagian tak berlabel dari basis data kami secara lebih terperinci.
Efek terabaikan yang menyebabkan perbedaan antara pola simulasi dan pola yang berasal dari eksperimen sebagian besar diketahui. Efek yang tidak diperhitungkan dapat mencakup orientasi kristalit yang disukai, variasi ukuran butiran, cacat kristal, dampak suhu pada proses hamburan, tegangan internal, non-monokromatisitas sumber sinar-X, dan fluoresensi yang disebabkan oleh sinar-X [ 21 , 32 , 33 ]. Selain itu, pengaturan eksperimen yang bervariasi menghasilkan pola difraksi bubuk yang berbeda pada sampel yang sama. Fitur yang dapat bervariasi antara pengaturan eksperimen mencakup bentuk puncak difraksi, panjang gelombang dan polarisasi sumber sinar-X yang digunakan, dan geometri detektor [ 21 , 32 , 33 ]. Sudut hamburan yang direkam juga dapat sedikit dipalsukan jika sampel dipindahkan dari posisi yang dimaksudkan [ 21 , 34 ]. Karena efek ini dan lebih banyak efek terabaikan diintegrasikan ke dalam proses simulasi, data difraksi bubuk nyata dapat digunakan untuk mengevaluasi seberapa dekat data simulasi cocok dengan data nyata. Meskipun perbandingan langsung hanya mungkin dilakukan pada pola berlabel, membandingkan kekuatan dan prevalensi fitur antara data simulasi dan data nyata tetap dapat memberikan informasi tentang kesetiaan simulasi. Mempertimbangkan semua efek yang diabaikan tanpa membuat perkiraan akan menimbulkan biaya komputasi yang signifikan yang akan menurunkan ukuran data pelatihan yang dihasilkan. Pendekatan yang lebih efisien adalah dengan menggunakan data eksperimen nyata untuk mengidentifikasi efek yang memiliki dampak terbesar dalam praktik dan memodelkannya secara heuristik.
Cara kedua di mana data eksperimen tak berlabel dapat berfungsi untuk menjembatani kesenjangan kinerja antara domain simulasi dan eksperimental adalah melalui pembelajaran transfer. Tujuan pembelajaran transfer adalah untuk mentransfer kemampuan model yang dipelajari pada domain sumber di mana data berlabel berlimpah ke domain target di mana data berlabel jarang [ 35 ]. Dalam konteks ini, domain sumber adalah pola difraksi serbuk simulasi dan domain target adalah pola difraksi serbuk eksperimental. Banyak pendekatan untuk pembelajaran transfer telah diusulkan, khususnya dalam domain klasifikasi gambar [ 36 , 37 ]. Teknik-teknik yang ada ini dapat diadaptasi untuk memfasilitasi pembelajaran transfer dalam konteks pola pXRD. Seddiki et al. telah berhasil menerapkan pembelajaran transfer dalam domain spektrometri massa untuk meningkatkan akurasi model klasifikasi spektrum massa [ 38 ]. Karena data spektrometri massa dan data pXRD adalah satu dimensi, karya ini menunjukkan manfaat pembelajaran transfer dalam pengaturan yang mirip dengan pXRD.
Basis data opXRD ditujukan sebagai inisiatif yang terus berkembang dan digerakkan oleh komunitas. Basis data yang kami sajikan di sini adalah versi pertama, tetapi kami berharap untuk lebih meningkatkan ukuran basis data melalui keterlibatan aktif dengan komunitas pXRD. Tujuan utama kami adalah untuk meminimalkan upaya dan dengan demikian hambatan untuk menyumbangkan data eksperimen ke basis data opXRD. Dengan demikian, kami mengembangkan program yang membantu menemukan dan berbagi data dari komputer lab pXRD. Pengguna dapat memilih jenis file pXRD yang paling umum, program ini mencantumkan semua file jenis itu, dan pengguna dapat memilih atau membatalkan pilihan folder atau file tertentu untuk dibagikan. Kontribusi yang dipilih akan diunggah ke opXRD, diproses ke format file umum, dan—jika diinginkan—diterbitkan di Zenodo atas nama kontributor, sebelum menjadi bagian dari basis data opXRD. Jika label tersedia, label tersebut juga dapat dibagikan dengan opXRD. Rincian lebih lanjut dapat ditemukan di situs web opXRD ( https://xrd.aimat.science/ ). Tinjauan umum proses ini diberikan pada Gambar 2 di bawah ini.
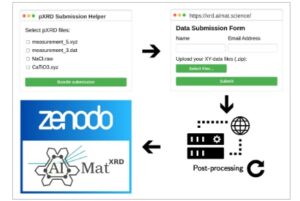
GAMBAR 2
Buka di penampil gambar
Kekuatan Gambar
Tinjauan umum alur pengumpulan data. Kumpulan data dikirimkan menggunakan formulir pengiriman daring, secara opsional dengan bantuan perangkat lunak pembantu pengiriman kami. Setelah pasca-pemrosesan dan homogenisasi data, kami menawarkan pembuatan entri Zenodo untuk setiap pengiriman pengguna dan selanjutnya menyertakan pengiriman tersebut dalam basis data opXRD.
Seperti yang dikemukakan oleh Aranda dan Kroon-Batenburg et al. [ 39 , 40 ], berbagi data difraksi bubuk mentah tidak hanya demi kepentingan penelitian pembelajaran mesin, tetapi juga sejalan dengan prinsip sains terbuka. Ini memajukan kemampuan peneliti lain untuk mereproduksi karya yang diterbitkan dan pada gilirannya menambah kredibilitas penerbit data. Dibandingkan dengan menerbitkan data secara individual, menerbitkan data pada basis data opXRD memiliki manfaat tambahan untuk berkontribusi pada kumpulan data yang besar dan homogen dengan antarmuka yang terstandarisasi. Ini membuat data lebih mudah diakses oleh peneliti lain dan memberikan nilai lebih kepada peneliti yang mencari data dalam jumlah besar. Namun, anotasi data lebih lanjut dengan metadata diperlukan untuk sepenuhnya memenuhi prinsip data FAIR.
Basis data opXRD berisi pola pXRD dari material fase tunggal dan multifase dari berbagai macam kelas material, termasuk material entropi tinggi, perovskit, dan katalis komersial. Beberapa data XRD dikumpulkan pada lapisan tipis dan bukan pada sampel bubuk asli, yang dapat memengaruhi kualitas data terkait resolusi struktur penuh. Selain itu, beberapa data dikumpulkan dalam geometri sudut grazing dan bukan dalam geometri Bragg–Brentano yang biasa digunakan dalam difraksi bubuk. Berbagai macam sampel eksperimen yang tersedia yang terdapat dalam basis data opXRD memungkinkan penerapan pendekatan ML terkini pada domain analisis pXRD. Kami berharap bahwa basis data opXRD dapat mendorong penelitian ML di bidang ini menuju alur kerja analisis otomatis yang lebih canggih yang dapat mempercepat penelitian ilmu material melalui aplikasi siap pakai dalam jalur eksperimen throughput tinggi. Rincian eksperimen kelompok penelitian yang berkontribusi pada basis data opXRD dibahas di Bagian 3 . Deskripsi terperinci tentang cara memperoleh dan menggunakan data opXRD diberikan di Bagian 4 , dan Bagian 5 menjelaskan bagaimana data lebih lanjut dapat disumbangkan.
1.1 Tinjauan Analisis pXRD Berbasis Pembelajaran Mesin
Untuk menunjukkan perlunya kumpulan data seperti yang disajikan dalam publikasi ini, kami sekarang membahas beberapa pendekatan terkini yang menerapkan metode pembelajaran mesin pada tugas klasifikasi dan regresi untuk difraktogram bubuk.
Pada tahun 2020, Lee et al. melatih jaringan saraf konvolusional dalam (CNN) menggunakan difraktogram simulasi berdasarkan struktur dari ICSD, yang mampu mengklasifikasikan fase yang terjadi dalam difraktogram dari kumpulan senyawa tertentu [ 41 ]. Pada tahun 2022, mereka selanjutnya mengembangkan model berdasarkan jaringan saraf konvolusional penuh dan enkoder transformator yang memprediksi sistem kristal, grup ruang, dan sifat struktural lainnya, seperti celah pita [ 42 ]. Dengan model terbaik mereka untuk prediksi sistem kristal pada struktur ICSD, mereka mencapai akurasi uji sebesar 92,2%. Pada tahun 2017, Park et al. mencapai akurasi uji sekitar 81% untuk CNN, yang mengklasifikasikan grup ruang dari difraktogram fase tunggal yang disimulasikan [ 12 ].
Analisis regresi pada parameter kisi dalam kerangka kerja yang lebih luas yang mencakup semua kelas material dilakukan oleh Chitturi et al. [ 18 ] pada tahun 2021. Mereka mengembangkan CNN yang berbeda untuk setiap sistem kristal, memanfaatkan kumpulan data gabungan dari ICSD dan Cambridge Structural Database, dan berhasil mencapai persentase kesalahan absolut rata-rata sekitar 10% untuk panjang kisi, meskipun mereka mengalami kesulitan dalam memprediksi sudut secara akurat. Pada tahun 2024, Zhang et al. memperkenalkan jaringan saraf perhatian-diri konvolusional yang dilatih pada pola simulasi untuk mengklasifikasikan jenis kristal [ 20 ]. Model mereka diuji pada 23.073 struktur kristal anorganik unary, biner, dan terner yang bersumber dari COD. Studi ini mengamati penurunan kinerja yang nyata ketika model pra-terlatih diterapkan pada pola eksperimen nyata dibandingkan dengan data simulasi. Namun, pekerjaan terbaru mereka [ 21 ] mengusulkan penggunaan deskriptor puncak konvolusional yang mempertimbangkan geometri detektor, yang mengurangi kesenjangan kinerja dalam pengujian benchmark mereka.
Jaringan saraf yang dilatih murni pada difraktogram eksperimental dapat bekerja dengan baik ketika rentang sampelnya sempit dan datanya hanya dikumpulkan pada satu mesin [ 13 , 43 ]. Namun, dalam pengaturan yang lebih umum dengan rentang sampel yang diselidiki dan difraktometer yang digunakan, melatih jaringan saraf murni pada difraktogram eksperimental menjadi tidak layak. Ini karena terbatasnya ketersediaan difraktogram eksperimental berlabel relatif terhadap cakupan tugas. Namun, pada tahun 2023, Salgado et al. [ 31 ] menunjukkan bahwa menambahkan sebagian kecil pola eksperimental ke set data pelatihan yang disimulasikan meningkatkan kinerja pada pola eksperimental yang tidak terlihat. Mereka menggunakan 50% dari pola eksperimental yang terdapat dalam basis data RRUFF dan menambahkannya ke set pelatihan simulasi mereka yang besar. Kemudian mereka menguji kinerja model mereka pada separuh lainnya dari basis data RRUFF dan mencapai peningkatan kinerja dalam akurasi klasifikasi grup ruang 230 arah sebesar 11 poin persentase dibandingkan dengan model yang sama yang hanya dilatih pada pola simulasi.
Pada tahun 2024, Schuetzke dkk. melatih pengklasifikasi untuk mengklasifikasikan apakah difraktogram berasal dari sampel amorf, fase tunggal, atau multifase [ 44 ]. Karena kurangnya pXRD eksperimental, mereka membangun jalur untuk menambah difraktogram simulasi dari struktur referensi dengan, antara lain, sedikit memvariasikan kisi kristal yang mendasarinya. Untuk struktur spinel, mereka melaporkan akurasi 100%, tetapi mereka juga membuktikan bahwa pendekatan mereka dapat ditransfer ke kumpulan data lainnya.
Pada tahun 2023, Schopmans et al. menyajikan pendekatan untuk menghasilkan struktur kristal sintetis dan pola pXRD yang sesuai dengan cepat selama proses pelatihan [ 14 ]. Pendekatan ini mengatasi masalah ukuran kumpulan data terbatas, yang membatasi kedalaman jaringan saraf yang dapat dilatih. Namun, akurasi turun secara substansial ketika kami menerapkan model klasifikasi grup ruang kami ke pola eksperimental dari basis data RRUFF. Menambah pola simulasi kami dengan latar belakang, derau, dan pengotor membantu membawa difraktogram simulasi lebih dekat ke yang eksperimental, membuat model yang dilatih pada mereka lebih berkinerja pada difraktogram eksperimental. Namun, proses penambahan ini dapat ditingkatkan dengan menggabungkan statistik latar belakang dan derau dari basis data pXRD eksperimental yang lebih luas, seperti yang disajikan dalam publikasi ini.
Terlihat jelas bahwa semakin umum tugasnya, semakin menantang transfer ke data eksperimen. Misalnya, tugas klasifikasi grup ruang di semua sistem material sangat umum. Oleh karena itu, mentransfernya ke aplikasi pada pola difraksi eksperimental sulit dilakukan [ 14 , 23 , 42 ]. Sebaliknya, ada beberapa pendekatan yang berhasil yang juga bekerja dengan baik pada data eksperimen, tetapi sebagian besar adalah metode yang melakukan penentuan fase dalam ruang senyawa terbatas, sehingga membuat tugasnya kurang rumit [ 41 , 44 ].
Volume pola pXRD eksperimental saat ini tidak cukup untuk melatih model ML secara efektif, yang menyoroti kebutuhan mendesak untuk basis data pXRD eksperimental yang komprehensif. Model ML yang paling canggih saat ini dilatih pada sekitar 10 5 −10 6 difraktogram yang disimulasikan [ 14 , 31 ]. Ini, sejauh pengetahuan kami, dua orde besaran lebih besar dari kumpulan data eksperimental terbesar yang dikurasi saat ini, PDF-5+, dengan sekitar 2 × 10 4 pola eksperimental. Ini bahkan satu orde besaran lebih besar dari sekitar 10 5 difraktogram tak berlabel dalam versi awal kumpulan data opXRD yang kami sajikan di sini.
Untuk membuat identifikasi data pXRD berbasis ML praktis untuk penggunaan eksperimental dan mengotomatiskan prediksi struktur meskipun tidak memiliki data pelatihan eksperimental, dua pendekatan utama sangat penting. Pertama, mengembangkan metode simulasi yang lebih canggih untuk memperkirakan pola eksperimental dengan lebih baik [ 21 ] dengan menggunakan statistik dari difraktogram eksperimental. Kedua, membuat basis data eksperimental yang memungkinkan pembelajaran transfer untuk menjembatani kesenjangan antara data simulasi dan dunia nyata. Untuk kedua langkah ini, pengembangan opXRD sangat penting, karena akan memberikan tolok ukur eksperimental yang komprehensif bagi komunitas, memungkinkan perbandingan yang adil dari model dasar dan evaluasi yang akurat atas penerapannya dalam situasi eksperimental nyata.
2 Dataset yang Ada
Untuk mengontekstualisasikan opXRD dalam lingkungan data difraksi serbuk eksperimental saat ini, daftar di bawah ini memberikan gambaran umum tentang basis data struktur kristal terbesar yang menawarkan akses ke data difraksi serbuk eksperimental. Untuk gambaran umum tentang basis data ini, lihat Tabel 1 di bawah ini.
TABEL 1. Tinjauan umum basis data difraksi serbuk eksperimental: Kolom “OA” menunjukkan apakah basis data tersebut bersifat akses terbuka atau tidak. Ketersediaan komposisi kimia, grup ruang, parameter kisi, dan struktur lengkap sampel yang mendasarinya ditunjukkan oleh kolom “Comp.”, “Spg.”, “Lattice” dan “Full structure”, secara berurutan.
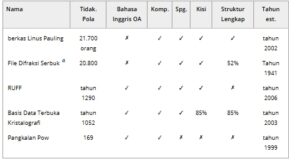
a PDF mencantumkan Material Platform for Data Science (MPDS) sebagai sumber basis data. Karena MPDS dihosting oleh proyek Pauling File, kemungkinan ada tumpang tindih yang signifikan dalam pola eksperimen yang tersedia dalam PDF dan Linus Pauling File.
2.1 Berkas Linus Pauling [ 45 ]
Linus Pauling File adalah database struktur kristal yang sebagian besar komersial yang diterbitkan dan dikelola oleh proyek Pauling File [ 29 ]. Saat ini didistribusikan sebagai data Pearson Crystal [ 46 ] dan Materials Platform for Data Science (MPDS) [ 47 ]. Database, yang pertama kali diterbitkan pada tahun 2002, saat ini berisi lebih dari 534.000 struktur kristal [ 47 ] dan 21.700 pola difraksi bubuk eksperimental yang sesuai [ 46 ]. Hal ini menjadikan Pauling file, sejauh pengetahuan kami, koleksi data difraksi bubuk eksperimental terbesar yang tersedia untuk para peneliti. Pada November 2024, data kristal Pearson tersedia untuk para peneliti melalui pembelian lisensi 1 tahun mulai dari titik harga 2200 € [ 48 ]. MPDS sebagian terbuka, dengan bagian terbuka dari data MPDS dapat diakses melalui antarmuka web [ 47 ]. Akses API ke MPDS lengkap dapat dibeli melalui lisensi 1 tahun mulai dari 9500€ [ 49 ]. Kami bertanya kepada proyek Pauling File apakah data difraksi serbuk eksperimental dapat diakses melalui API MPDS. Proyek Pauling File menanggapi bahwa data ini saat ini tidak disediakan melalui API, tetapi dapat ditawarkan di masa mendatang atas permintaan pelanggan.
2.2 File Difraksi Serbuk [ 50 ]
Powder Diffraction File (PDF), diterbitkan dan dikelola oleh International Center for Diffraction Data (ICDD), adalah kumpulan besar material dengan data difraksi bubuk yang menyertainya yang pertama kali diterbitkan pada tahun 1941 [ 28 ]. Menurut ICDD, rilis PDF terbaru, PDF5+, berisi lebih dari satu juta material dengan data difraksi bubuk yang menyertainya. Namun, karena sebagian besar pola difraksi bubuk ini disimulasikan, kami bertanya kepada ICDD tentang jumlah pola difraksi eksperimental dalam PDF5+. Kami diberitahu bahwa 20.800 pola dalam PDF5+ berasal dari eksperimen dan 10.954 pola ini disertai dengan koordinat atom dari struktur yang mendasarinya. Karena PDF5+ mencantumkan MPDS sebagai sumber basis data, kemungkinan ada tumpang tindih yang signifikan dalam pola eksperimental yang ditemukan dalam PDF5+ dan yang ditemukan dalam file Pauling. Saat ini, PDF5+ tersedia bagi peneliti melalui pembelian lisensi 1 tahun dengan harga mulai dari $6265. Namun, ICDD tidak mengizinkan peneliti untuk melatih model pembelajaran mesin pada data PDF5+, terlepas dari apakah model yang dihasilkan dipublikasikan [ 51 ].
2.3 RRUFF [ 52 ]
Basis Data Mineral RRUFF, pertama kali diterbitkan pada tahun 2006, menyediakan informasi terperinci tentang mineral, termasuk komposisi kimianya, kristalografi, dan data spektroskopi [ 27 ]. Dikelola oleh Universitas Arizona, basis data ini dibuat untuk berfungsi sebagai repositori publik untuk identifikasi dan penelitian mineral. Basis data ini berisi 1290 pola difraksi serbuk yang berasal dari eksperimen, masing-masing diberi label dengan parameter kisi dan komposisi struktur yang mendasarinya. Data RRUFF dapat diakses secara terbuka di situs web resminya [ 52 ].
2.4 Kristalografi Open Database [ 53 ]
Crystallography Open Database (COD) adalah kumpulan struktur kristal akses terbuka yang didirikan pada tahun 2003 [ 54 ]. Saat ini, kumpulan tersebut menyediakan lebih dari 500.000 struktur kristal. Dari berkas-berkas tersebut, 1052 berisi data difraksi serbuk eksperimental yang digunakan untuk menentukan struktur kristal yang mendasari sampel yang diteliti. Oleh karena itu, data difraksi serbuk eksperimental yang terdapat dalam COD sebagian besar diberi label dengan informasi struktur kristal lengkap. Data tersebut dapat diakses secara terbuka dalam bentuk berkas .cif di situs web resmi COD [ 53 ].
2.5 Basis Daya [ 55 ]
PowBase adalah basis data berisi 169 pola difraksi serbuk eksperimental yang sebagian besar tidak berlabel yang dikumpulkan dan dikelola oleh peneliti kristalografi Armel Le Bail sejak tahun 1999. PowBase adalah inisiatif yang disarankan dalam milis Structure Determination by Powder Diffractometry (SDPD), yang dikelola bersama oleh Le Bail. COD adalah inisiatif komunitas lain yang tumbuh dari milis ini. Hingga Maret 2025, semua 169 pola tersebut masih tersedia untuk diunduh secara gratis di situs web resmi [ 55 ].
Ada juga data difraksi serbuk yang tersedia untuk umum yang diunggah ke kumpulan data di Zenodo. Akan tetapi, data ini terbagi menjadi beberapa entri yang biasanya hanya berisi karya dari satu proyek penelitian. Selain itu, mengekstraksi data difraksi serbuk dalam skala besar terhambat oleh fakta bahwa data tersebut sering diberikan dalam berkas teks biasa dalam format yang tidak terstandarisasi, yang sulit diurai secara otomatis. Saat ini kami sedang merencanakan ekstraksi data difraksi serbuk secara sistematis dalam skala besar dari basis data seperti Zenodo dengan bantuan model bahasa yang besar. Data ini akan disertakan dalam rilis basis data opXRD mendatang.
Meskipun secara tegas bukan merupakan basis data difraksi serbuk, Basis Data Material Eksperimental Berkapasitas Tinggi (High-Throughput Experimental Materials Database/HTEM) oleh National Renewable Energy Laboratory (NREL) merupakan sumber data difraksi sinar-X yang berharga [ 56 ]. Saat ini, basis data HTEM berisi 65.779 sampel film tipis dengan data difraksi sinar-X yang sesuai [ 57 ]. Setiap entri basis data mencakup komposisi unsur dari sampel yang mendasarinya tetapi tidak memberikan informasi apa pun tentang strukturnya. Data HTEM bersifat akses terbuka dan dapat diunduh melalui API yang disediakan oleh NREL.
Selain dari database yang disebutkan di atas, kami juga telah menyelidiki beberapa sumber struktur kristal lainnya dalam pencarian data difraksi bubuk eksperimental. Sumber struktur kristal yang diselidiki tetapi tidak ditemukan mengandung sejumlah besar data difraksi bubuk eksperimental yang tersedia untuk umum termasuk Anorganic Crystal Structure Database [ 58 ], Cambridge Structural Database [ 59 ], Materials Project database [ 60 ], Crystallographic and Crystallochemical Database [ 61 ], Bilbao Incommensurate Crystal Structure Database [ 62 ], Mineralogy Database [ 63 ], IUCr Raw data letters [ 64 ], US Naval Research Laboratory Crystal Lattice-Structures [ 65 ], Athena Mineral database [ 66 ] dan Protein data bank [ 67 ]. Kurangnya data difraksi bubuk eksperimental dalam database ini diharapkan, karena sebagian besar solusi struktur dicapai melalui difraksi kristal tunggal.
3 Basis Data opXRD
Bekerja sama dengan beberapa lembaga penelitian lain, kami telah mengumpulkan basis data berisi 92.552 pola difraksi serbuk eksperimental. Dari pola-pola ini, 2.179 setidaknya sebagian diberi label dengan informasi struktural, dan 912 diberi label dengan struktur kristal lengkap dari material yang mendasarinya. Lembaga-lembaga penelitian berikut memberikan kontribusi data ke basis data opXRD: Pusat Penelitian Ilmiah Nasional Prancis (CNRS), Universitas Sains dan Teknologi Hong Kong (Guangzhou) (HKUST), Universitas California Selatan (USC), Laboratorium Nasional Lawrence Berkeley (LBNL), Laboratorium Federal Empa–Swiss untuk Sains dan Teknologi Material (EMPA), dan Institut Teknologi Karlsruhe (KIT). Kami telah mengambil langkah-langkah untuk memastikan validasi data melalui proses manual dan otomatis. Sebelum mengurai data, kami menetapkan format file dan organisasi data setiap pengiriman untuk memastikan bahwa file-file tersebut kompatibel dengan mekanisme penguraian khusus kami. Sebagai bagian dari proses penguraian otomatis, kami memfilter kumpulan data yang dikirimkan untuk mengecualikan pola dengan fitur yang tidak valid seperti hanya satu sudut unik yang terekam, sudut negatif, total sudut yang terekam kurang dari 50, atau semua intensitas menjadi nol. Setelah penguraian, kami juga memeriksa secara manual pilihan pola acak dari setiap kumpulan data yang dikirimkan untuk setiap anomali yang memerlukan penyelidikan lebih lanjut.
Kami menstandardisasi informasi struktural terkait sesuai dengan standar yang dijelaskan oleh Setyawan et al. [ 68 ] menggunakan PYMATGEN. Secara khusus, standardisasi ini memberlakukan konvensi sumbu kristal tunggal di seluruh data opXRD. Tabel 2 memberikan gambaran umum tentang kontribusi masing-masing lembaga.
TABEL 2. Tinjauan umum kontribusi terhadap basis data opXRD: Ketersediaan komposisi kimia, grup ruang, parameter kisi, dan struktur lengkap dari sampel yang mendasarinya ditunjukkan oleh kolom “Comp.”, “Spg.”, “Lattice” dan “Full structure.” secara berurutan.

Varians data dianalisis menggunakan analisis komponen utama (PCA). PCA dapat diterapkan pada datasetmathematical equationuntuk mengurangi jumlah komponen yang diperlukan untuk mendeskripsikan poinmathematical equationhingga beberapa toleransi dalam akurasi yang hilang. Dalam konteks PCA, rasio varians kumulatif yang dijelaskan adalah ukuran seberapa banyak varians dalam kumpulan data X dapat dijelaskan menggunakan sejumlah komponen tertentu. Untuk definisi PCA yang ketat dan rasio varians yang dijelaskan, kami merujuk ke literatur [ 69 ]. Di sini, PCA dilakukan pada kumpulan data pola difraksi sinar-X. Kumpulan data X ini adalah bagian darimathematical equationdengan N = 512 karena setiap polamathematical equationdistandarisasi agar memiliki 512 nilai intensitas yang tersebar merata dari 0° hingga 180° menggunakan zero padding dan interpolasi dengan spline kubik. Oleh karena itu, komponen maksimal yang mungkin diperlukan untuk mendeskripsikan kumpulan data difraksi dalam konteks ini adalah N = 512. Namun, jumlah maksimal komponen bahkan lebih rendah untuk kumpulan data yang berisi kurang dari 512 pola. Dalam kasus ini, jumlah maksimal komponen sama dengan jumlah pola dalam kumpulan data karena setiap pola dapat menambahkan paling banyak satu derajat kebebasan ke kumpulan data.mathematical equationOleh karena itu, jumlah maksimum komponen N maks dari kumpulan data pola X diberikan sebagai berikut:
![]()
Di Sinimathematical equationadalah jumlah nilai intensitas yang direkam per pola dan N pola adalah jumlah pola dalam dataset X. Gambar 3 di bawah ini menunjukkan rasio varians kumulatif yang dijelaskan atas fraksi komponen No. maksimal N maks seperti yang didefinisikan di atas. Dalam gambar ini, konvergensi yang lebih cepat dari rasio varians kumulatif menuju satu menunjukkan bahwa pola dalam dataset ini sebagian besar serupa. Misalnya, kontribusi oleh USC dan LBNL berisi banyak pola yang sangat mirip. Pola dalam dataset USC serupa karena sampel yang mendasarinya adalah semua variasi paduan CuNi dan CuAl. Pola yang dikirimkan oleh LBNL serupa karena berasal dari rekaman in-situ di mana beberapa ratus atau beberapa ribu pola dikumpulkan dari waktu ke waktu per sampel. Sebaliknya, kontribusi CRNS dan HKUST masing-masing adalah koleksi yang mencakup banyak proyek penelitian selama periode waktu yang besar dan dengan demikian menunjukkan tingkat variabilitas yang tinggi antara pola individual.
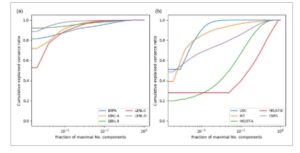
GAMBAR 3
Buka di penampil gambar
Kekuatan Gambar
Rasio varians yang dijelaskan atas fraksi jumlah maksimum komponen untuk setiap kumpulan data yang disumbangkan ke basis data opXRD: (a) Kontribusi EMPA, LBNL-A, LBNL-B, LBNL-C, LBNL-D, (b) kontribusi USC, INT, HKUST-A, HKUST-B, CNRS. Di sini, jumlah maksimum komponen mengacu pada N maks sebagaimana didefinisikan dalam Persamaan ( 1 ). Kumpulan data yang disumbangkan oleh lembaga yang sama diberi label secara alfabetis sesuai urutan yang dijelaskan dalam teks menjelang akhir bagian ini.
Gambar 4 mengilustrasikan distribusi properti pola dalam database opXRD. Hampir semua pola memiliki resolusi sudut lebih kecil darimathematical equation. Di sini, resolusi sudut didefinisikan sebagai rentang sudut terekam dibagi dengan jumlah nilai intensitas terekam sepanjang rentang tersebut. Untuk sebagian besar pola, sudut terekam terendah lebih kecil dari 30 dan sudut terekam tertinggi lebih kecil dari 120° . Distribusi sudut awal hingga akhir mengungkapkan bahwa semua difraktogram dimulai dalam jendela sempit antara 0 dan sekitar 50 , sementara mereka berakhir antara 50 dan 150 , dengan sebagian besar pola berkisar dari 0 hingga sekitar 70. Tidak seperti kebanyakan pendekatan ML yang menggunakan data sintetis pada rentang sudut penuh dengan resolusi tetap, set data opXRD memiliki rentang sudut dan resolusi yang sangat bervariasi. Oleh karena itu, bekerja dengan data ini memerlukan metode pra-pemrosesan tambahan seperti padding dan interpolasi, atau model ML yang lebih fleksibel di luar CNN standar.
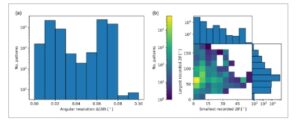
GAMBAR 4
Buka di penampil gambar
Kekuatan Gambar
Histogram yang merinci sifat semua pola difraksi dalam database opXRD: (a) distribusi resolusi sudut, (b) distribusi resolusi sudut terkecil dan terbesar yang tercatat.mathematical equationnilai-nilai.
Gambar 5 mengilustrasikan bagaimana properti struktural didistribusikan di antara struktur yang mendasari subset berlabel dari basis data opXRD. Sebagian besar struktur mencakup atom N, C, atau O, dan memiliki sel satuan yang berisi kurang dari 100 atom dan lebih kecil dari 10 Å 3 . Grup ruang yang paling umum mencakup ortorombikmathematical equation, monoklinikmathematical equation, dan kubikmathematical equation.
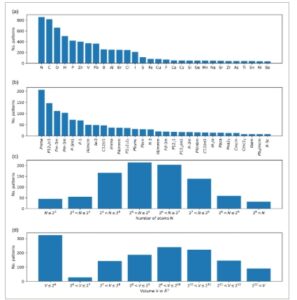
GAMBAR 5
Buka di penampil gambar
Kekuatan Gambar
Histogram yang merinci sifat-sifat struktur yang mendasari pola difraksi berlabel dalam database opXRD: (a) distribusi struktur yang mengandung elemen-elemen tertentu, (b) distribusi struktur yang mengandung grup ruang, (c) distribusi jumlah atommathematical equationterkandung dalam sel satuan, (d) distribusi volume sel satuanmathematical equationdi dalammathematical equation.
Berikut ini, kami akan menjelaskan kumpulan data yang disumbangkan oleh masing-masing kelompok penelitian dan lembaga yang bekerja sama. Setiap paragraf mencakup deskripsi bahan yang diteliti dan bagaimana data difraksi sinar-X dikumpulkan. Jika berlaku, keberadaan sampel lapisan tipis atau geometri difraksi atipikal ditunjukkan. Sebagian besar data dikumpulkan menggunakan sumber radiasi Cu, yang memilikimathematical equationpanjang gelombangmathematical equationÅ dan sebuahmathematical equationpanjang gelombangmathematical equationA.
3.1 Institut De Recherche De Chimie Paris, CNRS
Data pXRD eksperimental diekstraksi dari Crystallography Open Database (COD) [ 70 , 71 ]. COD, sepengetahuan kami, adalah koleksi akses terbuka terbesar dari struktur kristal eksperimental senyawa dan mineral organik, anorganik, dan logam-organik, yang berisi lebih dari 500.000 entri. Data dalam COD ditempatkan dalam domain publik dan dilisensikan di bawah Lisensi CC0. Dari seluruh basis data COD, 5432 struktur berisi setidaknya satu tag dari kamus CIF_POW, yaitu, tag yang berkaitan dengan studi difraksi serbuk. Ke-5432 struktur ini hanya mencakup 1% dari total basis data COD, tetapi ini diharapkan karena sebagian besar struktur kristal diselesaikan dari difraksi kristal tunggal. Dari 5432 file ini, sebagian besar hanya berisi metadata yang terkait dengan eksperimen difraksi serbuk, tetapi tidak menyertakan data mentah dari pola itu sendiri. Kami dapat mengekstrak pola pXRD eksperimental mentah dari total 1.052 file, setelah kurasi sejumlah kecil file dengan data yang jelas tidak valid.
Data pXRD dari database COD memiliki kualitas tinggi, dengan resolusi rata-ratamathematical equationdan jumlah rata-rata 9190 poin yang diukur per pola. Mereka mencakup ruang kimia yang luas, termasuk struktur organik, anorganik, dan hibrida, serta 75 elemen berbeda dalam tabel periodik.
3.2 Laboratorium Utama Informatika Material Kota Guangzhou, HKUST (GZ)
Dua set data disumbangkan ke basis data opXRD. Set data pertama (HKUST-A) adalah subset terpilih dari basis data sinar-X bubuk eksperimental skala kecil yang dikembangkan selama 2 tahun terakhir, yang disebut Set Data Eksperimen Publik Identifikasi Fase Sinar-X (XRed) ( https://github.com/WPEM/XRED ). Tujuan utama XRed adalah untuk mendukung kemajuan teknologi identifikasi fase cerdas dengan menyediakan fondasi untuk pengumpulan data dalam aplikasi pembelajaran mesin skala besar di masa mendatang. XRed terutama berfokus pada partikel logam dan logam-oksida, dengan data yang dikumpulkan menggunakan difraktometer seperti Empyrean 3.0, Aeris, dan Bruker D8 Advance, semuanya menggunakan sumber sinar-X Cu. Set data HKUST-A berisi 21 pola pXRD, masing-masing diberi label dengan file CIF yang sesuai yang mendokumentasikan struktur yang disempurnakan. Data dikategorikan berdasarkan sistem unsur dan mencakup file eksperimen asli, yang mencakup campuran fase tunggal hingga lima fase, serta campuran yang dirancang untuk berbagai tugas penelitian.
Selain XRed, basis data opXRD mengintegrasikan kumpulan data eksperimen yang terdiri dari data difraksi serbuk yang bersumber dari publikasi akses terbuka dan lembaga yang bekerja sama (HKUST-B). Lembaga-lembaga ini telah memberikan data dengan otorisasi penuh untuk keperluan penelitian. Dibandingkan dengan XRed, kumpulan data ini menawarkan cakupan unsur kimia yang lebih luas, meliputi kristal ionik, atomik, dan logam. Kumpulan data ini juga lebih besar, berisi 499 entri. Namun, tidak seperti XRed, entri data ini tidak disertai dengan berkas CIF.
3.3 Laboratorium Ilmu Permukaan dan Teknologi Pelapisan, Empa
Pustaka Zn–V–N kombinatorial disintesis menggunakan ko-sputtering frekuensi radio Zn dan V dalam plasma campuran Ar dan N 2 . Suhu pengendapan ortogonal dan gradien komposisi dibuat, menghasilkan suhu pengendapanmathematical equationC untuk sampel 1–9 danmathematical equationC untuk sampel 37–45. Komposisi untuk setiap sampel ditentukan menggunakan spektroskopi fluoresensi sinar-X (XRF), yang selanjutnya dikalibrasi melalui spektroskopi hamburan balik Rutherford (RBS) berdasarkan sampel yang dipilih. Semikonduktor yang baru diidentifikasi dan diisolasimathematical equationdiidentifikasi menunjukkan struktur wurtzite yang mengalami gangguan kation seperti yang diverifikasi oleh pengukuran GI-XRD dan SAED tambahan [ 72 ].
Perovskit halida timah diendapkan menggunakan pelapisan putar langkah tunggal seperti yang dilaporkan di tempat lain [ 73 ]. Pustaka timbal iodida metilamonium dengan berbagai tingkat residumathematical equationdiendapkan menggunakan prosedur dua langkah yang melibatkan penguapan termalmathematical equationdan pelapisan putar berikutnya dari larutan metilamonium. Fraksi fase relatif diukur menggunakan pemindaian sudut azimut suplementer yang digabungkan dengan faktor struktural dan faktor geometris seperti yang dilaporkan di tempat lain [ 74 ]. Pustaka perovskit timbal anorganik sepenuhnya disiapkan menggunakan penguapan bersama termal garam halida timbal dan cesium. Semua pustaka perovskit halida logam diukur dalam kubah gas inert transparan sinar-X yang dibuat khusus, yang menghasilkan adanya fitur tambahan kecil di dalammathematical equationrentang. Untuk semua pustaka kombinatorial yang fase-fasenya ditentukan, rangkaian fase yang lengkap dilaporkan dalam metadata.
Data XRD diukur menggunakan Bruker D8 Discover yang dilengkapi dengan sumber radiasi Cu dalam geometri Bragg–Brentano. Untuk kumpulan data yang dilaporkan, instrumen tersebut dilengkapi dengan cermin Goebel yang secara efektif menghilangkan radiasi Cu K β . Kumpulan data tersebut berasal dari eksplorasi kombinatorial ruang komposisi Zn–V–N, serta data yang dikumpulkan dari berbagai aktivitas penelitian pada semikonduktor perovskit halida logam yang lebih mapan. Semua data dikumpulkan dari lapisan tipis yang diendapkan pada kaca borosilikat. Lapisan Zn–V–N menunjukkan beberapa orientasi keluar bidang yang istimewa, sedangkan untuk perovskit orientasi istimewanya minimal, yang mengakibatkan adanya semua pantulan.
3.4 Institut Nanoteknologi, KIT
Data difraksi sinar-X dikumpulkan dari berbagai proyek penelitian yang dilakukan di Institut Nanoteknologi selama 10 tahun terakhir. Bagian utama dari penelitian difokuskan pada material entropi tinggi, yang melibatkan penggabungan banyak elemen berbeda ke dalam struktur fase tunggal, yang menyebabkan pergeseran puncak atau pemisahan fase. Sebagian besar material kompleks multikomponen tersebut muncul dalam berbagai struktur, termasuk garam batu, spinel, fluorit, perovskit, dan delafossit. Sampel disiapkan dalam bentuk bubuk atau curah; oleh karena itu, XRD bubuk dilakukan pada sampel dengan ketinggian yang disesuaikan. Sampel disiapkan menggunakan berbagai teknik sintesis, sebagian besar sintesis kimia padat atau basah, untuk mendapatkan struktur yang diinginkan. Akibatnya, ukuran partikel dan kristalinitas bervariasi secara signifikan. Set sampel juga mencakup sampel yang tidak berhasil diukur atau fasenya tidak dapat diidentifikasi.
Data difraksi sinar-X dikumpulkan pada Bruker D8 Advance menggunakan sumber radiasi Cu atau difraktometer STOE Stadi P yang dilengkapi dengan sumber sinar-X Ga-jet. Sampel awalnya direkam untuk berbagai proyek penelitian selama sepuluh tahun terakhir dan diukur dengan ukuran langkah yang berbeda, waktu per langkah, dan pada rentang sudut yang berbeda, tetapi semuanya menggunakan radiasi Cu K α atau Ga K β . Sampel sebagian besar mengandung oksida logam transisi, sulfida, dan fluorida. Untuk meningkatkan statistik, sampel diputar selama seluruh pengukuran. Beberapa sampel yang peka terhadap udara diukur menggunakan kubah polimer transparan untuk perlindungan. Kubah ini menyebabkan peningkatan kebisingan latar belakang selamamathematical equationdan resolusi pola sedikit menurun.
3.5 Institut Penelitian dan Teknologi Katalisis, KIT
Berbagai sampel dianalisis, termasuk katalis komersial, bahan referensi massal, partikel oksida logam berpori, dan nanopartikel. Yang terakhir disintesis melalui rute benzil alkohol bebas surfaktan [ 75 , 76 ]. Oksida kobalt (CoO ataumathematical equation) dan cerium oksida (mathematical equation) nanopartikel berada dalam kisaran ukuran 4−16 nm menurut persamaan Scherrer. Serangkaian partikel berporimathematical equationbahan-bahan yang dibuat dengan kalsinasi boehmite (AlOOH) pada berbagai suhu, merupakan sampel kristal dengan struktur jarak jauh terbatas dan berbagai kontribusimathematical equationpolimorf.
Difraksi sinar-X (XRD) dilakukan dengan X’Pert Pro MPD (Panalytical) dalam geometri Bragg–Brentano menggunakan sumber sinar-X Cu. Pola diperoleh dalammathematical equationkisaran 5−80 ∘ dengan ukuran langkah 0,016711 ∘ atau 0,033420 ∘ dan total waktu akuisisi 40–120 menit. Penelitian ini telah dilakukan dengan dukungan Angelina Barthelmeß, Elisabeth Herzinger, dan Henning Hinrichs.
3.6 Divisi Pengecoran Molekuler & Divisi Sumber Cahaya Canggih & Ilmu Kimia, LBNL
Secara total, empat kumpulan data berbeda dikumpulkan. Kumpulan data pertama (LBNL-A) dikumpulkan dari larutan prekursor perovskit halida logam tiga kation yang di-spin-coating dan annealing dengan komposisimathematical equation(mathematical equation mathematical equation)mathematical equation(mathematical equationmathematical equation) 3 ke berbagai substrat. Di sini, MA adalah singkatan dari Methylammonium dan FA adalah singkatan dari Formamidinium. Substrat tempat larutan ini dilapisi meliputi kaca, yang bersifat amorf, danmathematical equationwafer, yang merupakan kristal tunggal. Substrat lainnya adalah tumpukan kaca/indium timah oksida, tumpukan GaAs/CIGS, dan tumpukan kaca/CIGS. Di sini, CIGS merupakan singkatan dari tumpukan Mo, Cu (In, Ga)mathematical equation, Cds, dan ZnO. Beberapa substrat juga dilapisi dengan lapisan tunggal MeO-2PACz yang dapat merakit sendiri. Substrat GaAs disiapkan oleh Dr. Jiro Nishinaga dari Institut Nasional Sains dan Teknologi Industri Lanjutan (AIST) di Jepang [ 77 ] dan substrat kaca/CIGS oleh Dr. Christian Kaufmann dan timnya di Helmholtz-Zentrum Berlin (HZB) di Jerman [ 78 ]. Pengumpulan data dilakukan secara in situ selama pengendapan film tipis menggunakan tahap pelapisan putar dan pemanasan yang dibuat khusus [ 79 ].
Dataset kedua (LBNL-B) dikumpulkan dari larutan prekursor perovskit halida logam pelapisan putar dengan berbagai komposisimathematical equationdilapisi dengan spin pada substrat kaca. Di sini, MA = Methylammonium dan x = 0, 0,33, 0,5, 0,67, 1. Substrat dipanaskan terlebih dahulu pada suhu yang berbeda, termasukmathematical equationC,mathematical equationC,mathematical equationC, danmathematical equationC, dan proses spin-coating dilakukan pada suhu konstan pada substrat yang dipanaskan terlebih dahulu. Untuk kedua set data, data difraksi diukur secara terus-menerus selama spin-coating, induksi kimia kristalisasi, dan annealing sampel, padamathematical equationC danmathematical equationC masing-masing. Data difraksi direkam dengan frekuensi sekitarmathematical equationDanmathematical equation. Setiap pengukuran in situ terdiri dari sekitar 500–1000 difraktogram individu. Bergantung pada substratnya, setiap rangkaian difraktogram menunjukkan evolusi dari substrat saja menjadi kombinasi perovskit polikristalin,mathematical equation, dan substrat melalui beberapa fase antara.
Untuk kedua set data ini, data XRD eksperimental dikumpulkan di garis sinar 12.3.2 Advanced Light Source, sinkrotron di Lawrence Berkeley National Laboratory. Data dikumpulkan menggunakan energi foton 10mathematical equation(mathematical equation Å), dipilih menggunakan monokromator Si (111). Pengukuran dilakukan dalam geometri insiden grazing, yaitu, menggunakan sudut insiden balok 1 ∘ . Gambar difraksi dua dimensi direkam menggunakan detektor area Dectris Pilatus 1 M pada sudut antara 34 ∘ dan 36 ∘ dengan jarak sampel ke detektor sekitar 190 mm. Data dua dimensi dikalibrasi menggunakanmathematical equation mathematical equationstandar kalibrasi dan terintegrasi sepanjang sudut azimut.
Kumpulan data ketiga (LBNL-C) dikumpulkan dengan mengamati evolusi fase sistem Mn-Sb-O dengan berbagai suhu annealing. Suhu yang digunakan untuk menganalisis struktur kristal sistem Mn-Sb-O dipilih tergantung pada jumlah transisi fase yang muncul untuk rentang suhu tertentu. Beberapa perubahan dalam struktur kristal muncul antara suhu ruangan dan 300 C dan transisi fase muncul dari 300 °C hingga 850 C. Tidak ada transisi fase yang muncul saat pendinginan. Oleh karena itu, struktur kristal diukur setiap 100 C antara suhu ruangan dan 300 C; setiap 50 C antara 300 C dan 850 C; dan setiap 200 C saat pendinginan. Laju pemanasan dan pendinginan ditetapkan untuk semua percobaan pada 50 C/menit dan waktu penahanan ditetapkan menjadi 2 menit.
Data ini dikumpulkan menggunakan difraktometer in situ Rigaku-SmartLab3 kW. Alat ini beroperasi dengan perangkat lunak SmartLab Studio II, yang dapat mengukur difraksi sinar-X selama proses annealing. Hal ini memungkinkan untuk secara langsung menunjukkan semua transisi fase saat annealing dalam berbagai atmosfer sepertimathematical equation, Ar, danmathematical equationTransisi fase dianalisis dengan alat XRD in situ hingga 850 °C dalam penelitian ini. Sebagian besar percobaan in situ dilakukan di bawah suhu 20% seperti udara.mathematical equationdan lingkungan Ar 80% (aliran Ar: 50 sccm,mathematical equationaliran: 10 sccm). Ketika lingkungan Ar 100% ditetapkan, aliran Ar sebesar 60 sccm dimasukkan. Mode Bragg–Brentano (BB) lebih disukai dalam hal geometri karena lebih disesuaikan dalam analisis fase langka sepertimathematical equationrutil. Langkah sudut yang digunakan dalam perekaman adalah 0,01 dan laju pemindaian adalah 10 /menit.
Kumpulan data keempat (LBNL-D) dikumpulkan dari proses pelapisan putar dua langkah menggunakan kerangka logam-organik (MOF) dalam larutan prekursor perovskit, yang diendapkan ke substrat kaca. Pada langkah pertama, MOF berbasis Zr tipe UiO-66 yang difungsikan dengan tiol skala nano (mathematical equation) telah ditambahkan kemathematical equationprekursor. Hal ini diikuti oleh pengendapan larutan campuran organik yang mengandung FAI, MACl, dan MABr pada langkah kedua. Penggabungan MOF membantu dalam menekan cacat kekosongan perovskit, sehingga meningkatkan stabilitas dan efisiensi perangkat. Untuk menyelidiki lebih lanjut pengaruh UiO-66-mathematical equationpada pembentukan lapisan tipis perovskit selama proses annealing, dilakukan percobaan GIWAXS dengan resolusi waktu. Pengukuran dilakukan menggunakan pengaturan yang mirip dengan LBNL-A dan B.
4 Penggunaan
Basis data opXRD dihosting di Zenodo ( https://zenodo.org/records/14254270 ) dan dapat diunduh oleh pengguna mana pun tanpa hambatan atau batasan apa pun.
Kami juga menyediakan pustaka Python ‘opxrd’ untuk mengunduh dan berinteraksi dengan mudah dengan kumpulan data. Pustaka opXRD dirancang untuk integrasi mudah dengan kerangka kerja pembelajaran mesin umum seperti PyTorch . Ini menjadikannya sumber daya yang ideal bagi para peneliti yang mengembangkan dan melakukan pembandingan strategi transfer sim-ke-nyata dalam analisis data pXRD. Petunjuk tentang cara memasang pustaka ini dapat ditemukan di repositori yang terkait dengan pustaka tersebut. Repositori pustaka ini terletak di https://github.com/aimat-lab/opxrd . Pustaka opxrd mencakup opsi untuk pemuatan data, standarisasi, pembuatan plot, dan konversi ke tensor PyTorch . Kami menyediakan Jupyter Notebook ( https://colab.research.google.com/github/aimat-lab/opXRD/blob/main/opxrd/usage.ipynb ) yang memamerkan fungsionalitas ini secara lebih terperinci. Notebook ini juga mengilustrasikan cara berinteraksi dengan basis data opXRD melalui Python.
5 Ringkasan dan Prospek
Dengan basis data opXRD, kurasi 92.552 pola difraksi sinar-X serbuk eksperimental yang tidak berlabel dan 2.179 yang setidaknya sebagian berlabel dari berbagai sistem material yang berbeda, kami menyediakan sumber pola XRD eksperimental terbesar yang tersedia saat ini. Dengan ini, kami mengatasi kebutuhan akan data eksperimental yang muncul saat mengembangkan algoritme dan alat analisis untuk data pXRD, baik berdasarkan pembelajaran mesin maupun pendekatan klasik. Data tersebut dapat digunakan untuk pengembangan metode aktual dan untuk pengujian. Kumpulan data kami adalah sumber daya yang berharga dan sejauh ini hilang untuk mendorong pengembangan lebih lanjut dalam analisis otomatis data XRD. Ke depannya, opXRD diharapkan memainkan peran penting dalam pengembangan pendekatan pembelajaran transfer tingkat lanjut yang mengintegrasikan data simulasi skala besar dengan pola eksperimental nyata, yang pada akhirnya mendorong otomatisasi dan akurasi analisis pXRD. Pekerjaan di masa mendatang juga akan mencakup evaluasi tolok ukur yang komprehensif untuk mengukur peningkatan kinerja yang dicapai dengan menggabungkan opXRD ke dalam jalur pembelajaran transfer.
Daripada proyek yang sudah selesai, basis data opXRD merupakan upaya berkelanjutan untuk mengumpulkan data XRD serbuk eksperimental. Kami mengundang semua orang yang bekerja dengan XRD serbuk eksperimental untuk mengirimkan data apa pun yang ingin mereka bagikan secara publik ke kumpulan data, untuk lebih meningkatkan utilitasnya dan dengan demikian membantu pengembangan lebih lanjut di bidang ini. Halaman pengiriman kami ( https://xrd.aimat.science/ ) akan terus tersedia untuk pengiriman data. Saat pengiriman baru masuk, versi terbaru dari basis data opXRD yang menggabungkan kumpulan data yang dikirimkan ini akan dirilis. Seiring dengan pertumbuhan basis data opXRD lebih lanjut, kami berharap dapat memperluas situs web ini untuk menjadi sumber daya komunitas yang komprehensif dari mana basis data dapat diatur. Sumber daya yang direncanakan di situs ini mencakup daftar kontributor, daftar versi, dan changelog serta pernyataan praktik pembuatan versi, lisensi, kutipan, dan atribusi yang komprehensif.
Kami akan terus memperbarui dan memelihara himpunan data dengan kiriman baru yang masuk.

